作为手机重度依赖症的小伙伴们,如果没有手机的日子该怎么办呢?现在智能手机里最核心的就是CPU(中央处理器)了,所以手机也是一个计算机系统。当你“开黑”和“吃鸡”的时候,你有没有感觉手机发烫并且开始变卡顿了?那么为什么会这样,我们就需要先了解计算机的结构。按照冯 诺依曼架构,一个最简单的计算机应该包括运算器、储存器、控制器、输入和输出端口这几个部分。其中最核心部分就是运算器了,主要由各种加法器和乘法器构成,用来完成各种逻辑运算操作。因此运算器能执行的操作有多快,将决定着一台计算机能力的强弱。整个运算的操作在控制器控制下,使要计算产生的数据在运算器和储存器之间进行传输。随着第四代计算机中引进超大规模集成电路后,这种架构的计算机面临着严重的技术瓶颈,即运算器和存储器之间的数据传输速度与运算器的数量相比有限。因为在运算器中数据传输速度依赖电子传递速率,与光速相比非常小且极易受到环境影响,所以当你的手机变得发烫的时候,电子传递速率将大大下降,你就被“卡”那里。此时运算器被迫不断地“等待”所需的数据传输到存储器或者从存储器传输出来。这个过程就好像两个伙伴共同完成一袋大米的搬运,A只需要一分钟就完成大米的装袋过程,而B需要一个小时将其递送给顾客,那个这时搬大米的完成程度将完全取决于B的动作快慢。发展到今天,随着现在 CPU 计算性能的飞跃发展,但是电子较低的传输速率再也不能满足超高速、低延迟的海量数据处理的需求。
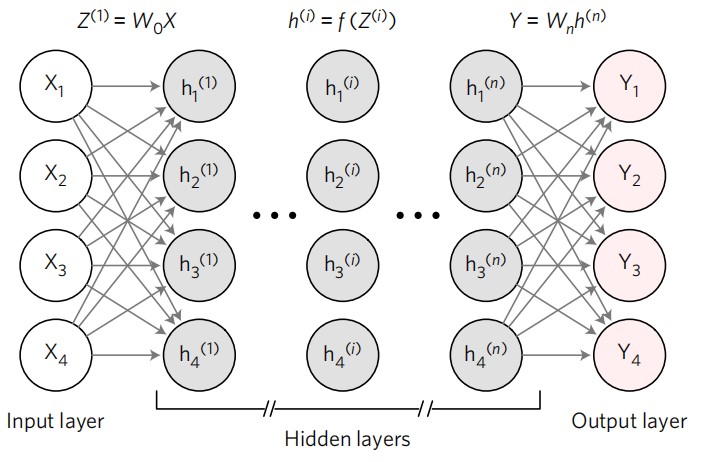
图1:深度神经网络模型
目前全球用户对人工智能和高速通信越来越依赖,这导致现在对计算能力的需求变得越来越大。自人工智能概念创立起来,以神经网络为代表的人工智能技术广泛地应用于语音识别、图像识别、医疗检测和心理学研究等领域。由于超大信息容量和神经网络特殊的数据结构,人工智能神经网络往往需要十分复杂的矩阵运算。以人工智能实现图像识别这种案例来说,首先将图片进行采集,并且以二维像素分布的形式输入计算机,并且将输入的数据进行各种格式转换,并且通过神经网络中数以千万的神经节点进行计算,最终得到结果。因此越复杂的机器学习任务,所需要的计算性能也就越高。过去主要依靠提升半导体制造技术来增多集成电路数量来提高性能的方式,随着摩尔定律的不适用变得越发困难。因此迫切需要一种新的矩阵计算形式来实现高性能和高效的矩阵计算。

图2:实现矩阵乘法的光子处理器示意图
“上帝说要有光,于是就有了光”,光子学研究作为一个年轻而又充满活力的研究领域,是研究以光子为信息载体的科学。光子学与信息学的第一次完美结合可能是在光通信,现在我们使用的主干网络就是基于光纤通信而建立的。但是如果让光子不仅仅充当信息的承载者,而是让光子也能够完成计算是一件多么神奇的事情。例如对于现在机器学习中使用最多的数据形式——图像文件来说,它本身就具有光学信息,但是传统计算机需要CCD将其转置为二进制信息,这个过程往往计浪费大量算力。那么你有听说过光子处理器吗?其实从上世纪五十年代开始,科学家们就一直想操控光子实现计算功能。目前基于矩阵乘法方式的光子运算器得到了迅速发展,可以广泛应用于光信号处理、人工智能和光神经网络等等领域。目前来说,光子矩阵乘法计算的研究方法目前主要分为三类:平面波转换法、马赫-曾德尔干涉仪法和波分多路复用法。但是基于平面波转换法和波分夺路复用法的光子处理器一般体积都较大且不易集成化,因此不适合进行大规模商用。而基于马赫-曾德尔干涉仪(MZI)的光波导结构,将十分有利于光子处理器的芯片化。
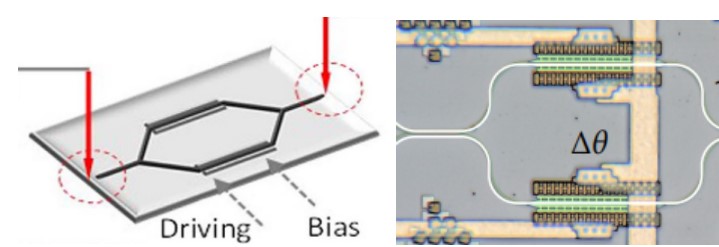
图3:基于马赫-曾德尔干涉仪的光信号处理单元
2017年发表在《Nature Photonics》上的论文引起人们的注意,该论文通过在光子集成芯片上实现一种可编程光子处理器。该处理器使用56个可编程的MZI单元集成一个处理器,可以实现全光学前馈神经网络架构的计算结构,并且在图像识别方面展现了其特有的优势。所谓的光子集成芯片,就是将例如光栅、耦合器、光开关、激光器、光电探测器等等这些特殊的光子器件进行组合并小型化后集成在一些特殊材料衬底上,以完成预设功能。在这个可编程光子处理器中,使用的最重要的基础单元就是基于MZI原型的光波导单元。
这个光波导单元的工作原理是,输入的光信号被波导耦合器分成相等的两路光信号分别进入干涉仪的两个光支路。两个光支路使用铌酸锂材料作为光波导,特点就是其折射率将会随外部偏置电压变化而发生变化,从而引起这段光支路中传输光波产生额外的相位变化。当两个光支路信号再次结合时,将会变成一个强度大小随着两个支路产生的相位差相关的光信号,而这个相位差恰恰由两个光支路各自控制的电压相关。这样就实现了光强度调制,输出变成一个输入信号与控制电压的乘积,实现乘法功能。简单来说,加载到两个光支路上的电压共同创造一个“光阀门”,并且电压的变化可以阀门的大小,控制当多个这样的干涉仪单元进行级联排列时,就可以完成复杂的矩阵运算。同大规模集成电路相比,该光子处理器使用光子作为信号传输媒介,当光子在该处理器中以光束进行传播的同时,就完成了乘法运算。这样的光子处理器十分适合于神经网络运行,例如将被识别物体的光学信息通过光纤传入该光子计算器,流经的每个神经元的节点就是可编程的最小干涉单元,通过反向传递算法对乘法器进行权重更改,并且在监督学习约束下完成神经网络模型的学习。由于光子处理器具有高容量和低延迟的矩阵信息处理能力,这将大大加快深度学习任务,并且保持整个运算功耗处于一个很低的水平。

图4:曦智科技于2019年推出的世界上第一款光子处理器原型机
为了推动光子处理器的实体化,这篇论文的作者沈亦晨在2017年创办了曦智科技,并在2019年推出了世界上第一款光子芯片原型机。除了实现矩阵乘法计算外,那么曦智科技是怎样通过干涉仪单元结构实现逻辑门的设计呢?根据该公式公开的专利文件显示,通过集成两个干涉仪单元和相位可控光波导,实现了与或和异或门的设计,因此光子处理器的功能将大大拓展。在2021年年底,曦智科技发布了他们的第二代高性能光子计算处理器PACE,其中含有超过万个光子器件,在1GHz频率下运行特定循环神经网络,其处理速度是GPU3080的数百倍。

图5:曦智科技发布的第二代高性能光子计算处理器PACE
但是目前来说,由于光子处理器与传统计算机处理的结构完全不同,需要重新设计其架构和工艺流程,并且将光子器件的数量进一步提升,在未来光子处理器将会在很多面临性能瓶颈的深度学习场景上大展身手。
参考文献:
1. Shen Y, Harris N C, Skirlo S, et al. Deep learning with coherent nanophotonic circuits[J]. Nature Photonics, 2017, 11(7): 441-446.
2. Long Y, Zhou L, Wang J. Photonic-assisted microwave signal multiplication and modulation using a silicon Mach–Zehnder modulator[J]. Scientific reports, 2016, 6(1): 1-6.
3. Zhou H, Dong J, Cheng J, et al. Photonic matrix multiplication lights up photonic accelerator and beyond[J]. Light: Science & Applications, 2022, 11(1): 1-21.
4. Fu Y, Hu X, Lu C, et al. All-optical logic gates based on nanoscale plasmonic slot waveguides[J]. Nano letters, 2012, 12(11): 5784-5790.
5. Nahmias M A, De Lima T F, Tait A N, et al. Photonic multiply-accumulate operations for neural networks[J]. IEEE Journal of Selected Topics in Quantum Electronics, 2019, 26(1): 1-18.
6. https://www.lightelligence.co/

 陕公网安备 61019002000969号
陕公网安备 61019002000969号


